All CS 3x projects are STRICTLY solo. You may not collaborate with other students.
Setup
Register for the project using the registration tool and clone the repository as explained in the setup instructions.
You MUST work solo on this project! You may not collaborate at all with anyone else! Please use the SSH link found at the picture after clicking the link in the registration email:
Task 0.
Bring over hashtable.c into the library directory.
Introduction
A trie is a particular kind of dictionary which maps “strings” to some type.
For example, here is a trie that represents the words
{adam, add, app, bad, bag, bags, beds, bee, cab}:

One reason we might use a trie over a hashmap is that it allows us to handle prefix queries more efficiently than looking at every key.
Trie Interface
In contrast to the dictionaries that we’ve implemented before, a trie is NOT
a general-purpose data structure. There is an extra restriction on the “key”
type; namely, it must be made up of “characters”. In the image above, this is
a char, but it can be really any type! For example, in a fully generic trie,
our “key type” could be an int*, and our “alphabet type” could be int.
In our implementation of tries, we will constrain our key type (dict_key_t) to
be char *. However, our alphabet type (alpha_t) will also constrained to be
char *! This gives us more flexibility in “chunking” strings. In the example
above, our alphabet is one-char strings (“a”, “b”, etc.). We could also have a
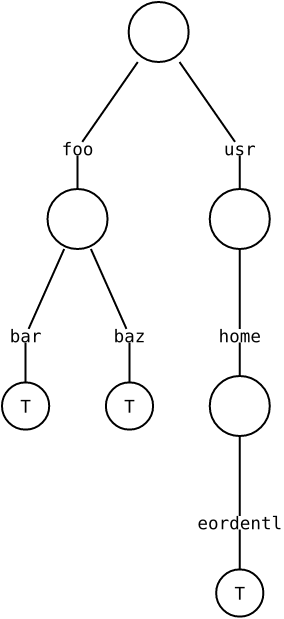
trie that stores paths as keys, and splits paths into segments. For example,
here is a trie that represents the paths {"/foo/bar", "/foo/baz", and "/usr/home/eordentl"}.
Trie Nodes and Triemap Functions
Our node implementation (include/trienode.h) is similar to what was shown in
lecture, but varies slightly. For complicated reasons, our nodes are dict_t,
where the map_impl is a trie_node_t. Instead of accessing children, you
should use dictionary functions directly on the “node” itself.
dict_t?
Because a trie_node_t owns its value, it must also know how to free its value.
However, the value_free function is passed to the trie, not the node! To get
around this, we make trie_node_t an implementation of dict_t, and store the
value_free in its custom functions. The cleaner interaction with
the children field through wrapper functions is a neat side-effect.
In order to use a generic key in a trie, we need to have a way to take keys
apart into their alphabet. We accomplish this with an “iterator”
(include/iterator.h), which mimics the Java Iterator API.
The trie_map_t stores a key_iterator_init, which takes a dict_key_t *,
and produces an iterator_t * that produces an alpha_t * on each call to
get_next.
Ownership is very tricky to handle between the various datastructures at play here. We will call out specific things to be aware of, but read the header file comments carefully for how ownership is or isn’t transferred with various functions.
Here, note that the iterator’s get_next function does not
transfer ownership of the alpha_t * to the caller. When you store an
alpha_t * in a node with dict_put, you must make a copy.
Your _triemap_put and _triemap_get functions must have time complexity
\(\Theta(d)\), where \(d\) is the number of “letters” in the key. These
functions work on the entire key, make sure to only add/find the exact key
asked for.
Task 1.
In trienode.c, implement the _trie_node_init function.
In triemap.c, implement the _triemap_init, _triemap_put, _triemap_get,
and _triemap_size functions. In _triemap_init, pass NULL as the
value_free when creating the root node.
When you are done, run make task1 to check your work.
Task 1 does not check for memory leaks. We now implement the freeing functions, and require that we no longer leak memory.
Task 2.
In trienode.c, implement the _trie_node_dict_free function.
In triemap.c implement the _triemap_free function.
Additionally, fix earlier functions to not leak memory.
Once you’ve implemented these functions, run make task2 to check your work.
This is due to “function pointer type compatibility” in C, which is a set
of rules for which functions we can call through a specific type of function
pointer. Specifically, function types are compatible iff their return types
are “compatible”, and all their argument types are “compatible”. The problem is
that void * is, surprisingly, not “compatible” with all pointers, by the C
standard’s definition of “compatible”!
This is a deep, dark corner of the C standard and how computers could possibly work.
triemap_is_prefix(trie, k) should true iff k is a prefix of some key in
the trie. For example, if "add" were a key in the trie and the alphabet was
single characters, then:
is_prefix("") = is_prefix(trie, "a") = is_prefix(trie, "ad") = is_prefix(trie, "add") = true.
This function is arguably one of the major reasons to use a trie over another implementation of a dictionary. Your implementation must have time complexity \(\Theta(d)\).
Task 3.
In triemap.c, implement the triemap_is_prefix function.
Once you are done, run make task3 to check your work.
Trie Traversal
We now turn to functions that need to iterate over every node in the trie. You will likely want to write these functions recursively, with an “accumulator” argument which “collects” the completions/keys as you recurse down the trie.
To support this functionality for generic keys, we also need a way to put keys back together. This is necessary because trie nodes don’t actually store their keys! We accomplish this with two pieces:
-
stack_t: implementation of the stack data structure that holdsvoid *. Seeinclude/stack.hfor details. -
alpha_accumulate: a stored function that converts astack_tofalpha_tto an allocateddict_key_t.
Unfortunately, due to the accumulator (and the fact that trie nodes don’t store
their keys), the dict_keys implementation for tries cannot behave like
our other dictionaries and return pointers to existing keys. The caller must
be sure to free the elements of the returned array, as well as the array itself.
When you iterate over the keys of a trie_node_t, those keys are owned
by that dictionary. A stack_t does not take ownership of the pointer, so
after you pop an alpha_t * from the stack, you should not free it! The
alpha_t * is still owned by the trie_node_t.
Task 4.
Implement _triemap_keys.
Once you are done, run make task4 to check your work.
For _triemap_keys, we know how large the returned array needs to be in advance;
this is not the case for triemap_get_completions. Therefore, we provide a
dynamic array (see include/dynamic_array.h), which automatically increases its
allocated capacity as necessary (like a resizing hash table).
You may find it useful to edit the recursive helper for _triemap_keys to use a
dynamic_array_t.
Task 5.
Implement triemap_get_completions. For this function, the high-level approach
you should follow is:
- Search for the node with the key
prefix.- If the node doesn’t exist, return.
- If the node exists, create a second iterator to convert the
prefixto astack_t.- DO NOT free the second iterator yet. The stack does not own its pointers, so if we free the iterator, accessing the stored pointers in the stack will cause use-afer-free errors.
- Recursively traverse the trie from the starting node, collecting keys into
a
dynamic_array_t(initial capacity 8). - Ensure the array is
NULL-terminated. - Retrieve the underlying pointer with
dynamic_array_get_data. - Free everything (iterator, stack, dynamic array), and return the stored pointer.
Once you are done, run make task5 to check your work.
_triemap_remove
Finally, implement _triemap_remove for your trie.
_triemap_remove(k) should delete k from the trie, as well as all of the nodes
that become unnecessary. One possible implementation of _triemap_remove
(called lazy deletion) would be to find k in the trie, and set its status
to EMPTY. You may not implement _triemap_remove as lazy deletion. Instead, you
must ensure that all leaves of your trie have values, with the exception of
the root. This function should also have time complexity \(\Theta(d)\).
_triemap_remove MUST be written recursively to receive any credit.
Task 6.
Implement _triemap_remove for a trie.
Once you are done, run make task6 to check your work.
In order to check your entire trie implementation, you can run make test.